TEACH: Temporal Action Compositions for 3D Humans
Abstract
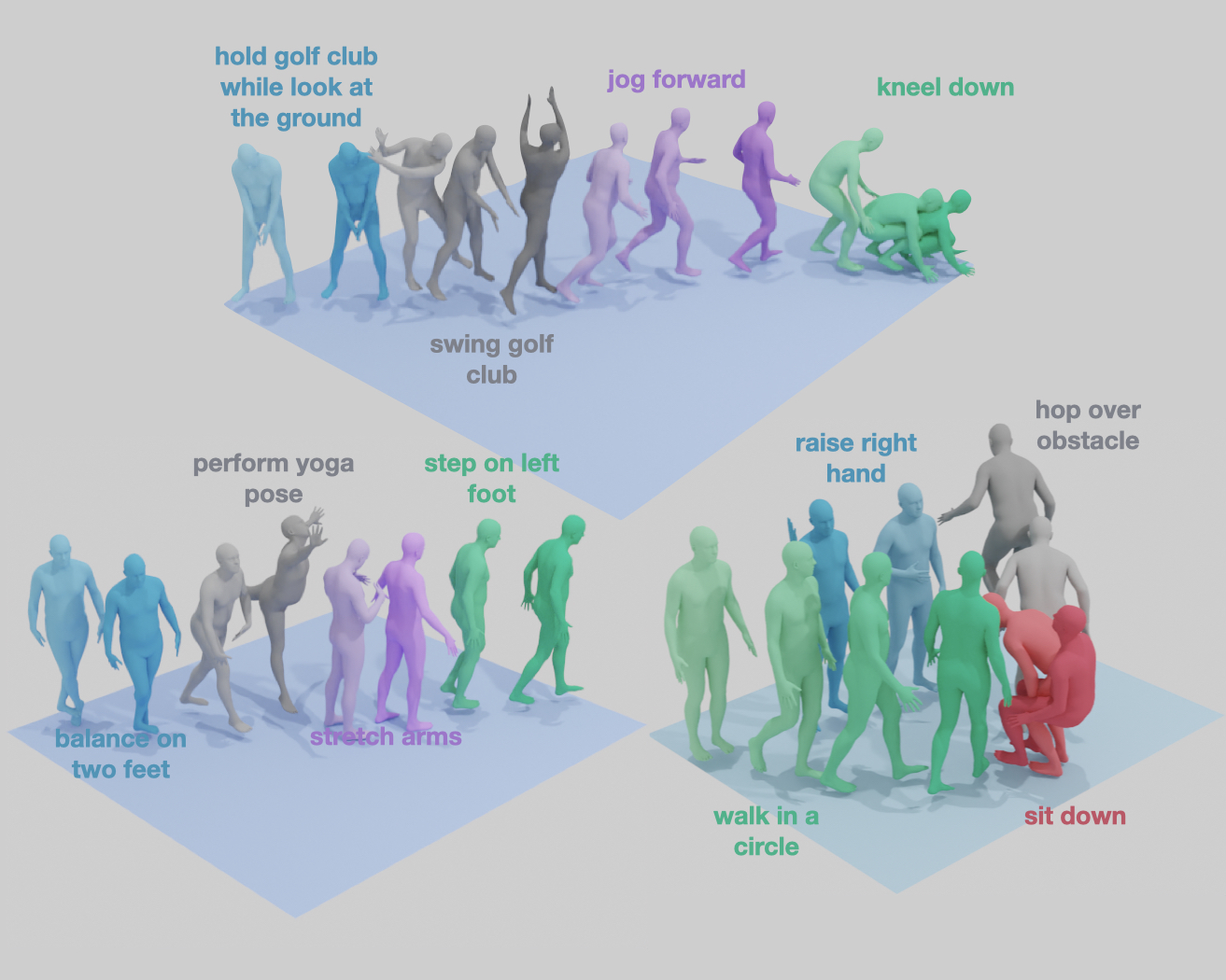
Given a series of natural language descriptions, our task is to generate 3D human motions that correspond semantically to the text, and follow the temporal order of the instructions. In particular, our goal is to enable the synthesis of a series of actions, which we refer to as temporal action composition. The current state of the art in text-conditioned motion synthesis only takes a single action or a single sentence as input. This is partially due to lack of suitable training data containing action sequences, but also due to the computational complexity of their non-autoregressive model formulation, which does not scale well to long sequences. In this work, we address both issues. First, we exploit the recent BABEL motion-text collection, which has a wide range of labeled actions, many of which occur in a sequence with transitions between them. Next, we design a Transformer-based approach that operates non-autoregressively within an action, but autoregressively within the sequence of actions. This hierarchical formulation proves effective in our experiments when compared with multiple baselines. Our approach, called TEACH for “TEmporal Action Compositions for Human motions”, produces realistic human motions for a wide variety of actions and temporal compositions from language descriptions. To encourage work on this new task, we make our code available for research purposes at teach.is.tue.mpg.de.
Supplementary Video
Video Results
More Information
Our models are available in the Download section for all the experiments done in the paper.
More information:
Citation
@inproceedings{TEACH:3DV:2022,
title = {{TEACH}: {T}emporal {A}ction {C}ompositions for {3D} {H}umans},
author = {Athanasiou, Nikos and Petrovich, Mathis and Black, Michael J. and Varol, G{\"u}l},
booktitle = {{International Conference on 3D Vision (3DV)}},
pages = {},
year = {2022}
}Acknowledgements
We thank Benjamin Pellkopfer for his IT support, Vassilis Choutas and Nefeli Andreou for their feedback, writing help and suggestions.
Contact
For questions, please contact nathanasiou@tue.mpg.de.
For commercial licensing, please contact ps-licensing@tue.mpg.de.